
If you approach Databricks interview questions expecting a standard FAANG-style experience, the interviews will feel unfamiliar very quickly. Databricks is not a consumer product company. It is a data platform company built around large-scale distributed systems, and its interviews reflect that reality.
From the beginning, Databricks evaluates whether you can reason about systems that process massive volumes of data reliably, efficiently, and predictably.
Databricks Is A Distributed Systems Company First
Databricks builds infrastructure that sits at the heart of data pipelines for thousands of companies. That means engineers are expected to understand how systems behave under load, how failures propagate, and how data correctness is preserved at scale.
Databricks interview questions often assume datasets that are far larger than memory and workloads that span multiple machines. You are not being tested on clever tricks. You are being tested on whether you understand the mechanics of real systems.
Why Databricks Interview Questions Feel More Open-Ended
Databricks interviews intentionally leave room for interpretation. You are expected to ask clarifying questions, define assumptions, and scope problems appropriately.
This mirrors real work at Databricks, where requirements evolve, and systems must adapt without breaking downstream users. Interviewers are listening for how you think through ambiguity, not just what solution you arrive at.
How Databricks Interviews Differ From FAANG And SaaS Interviews
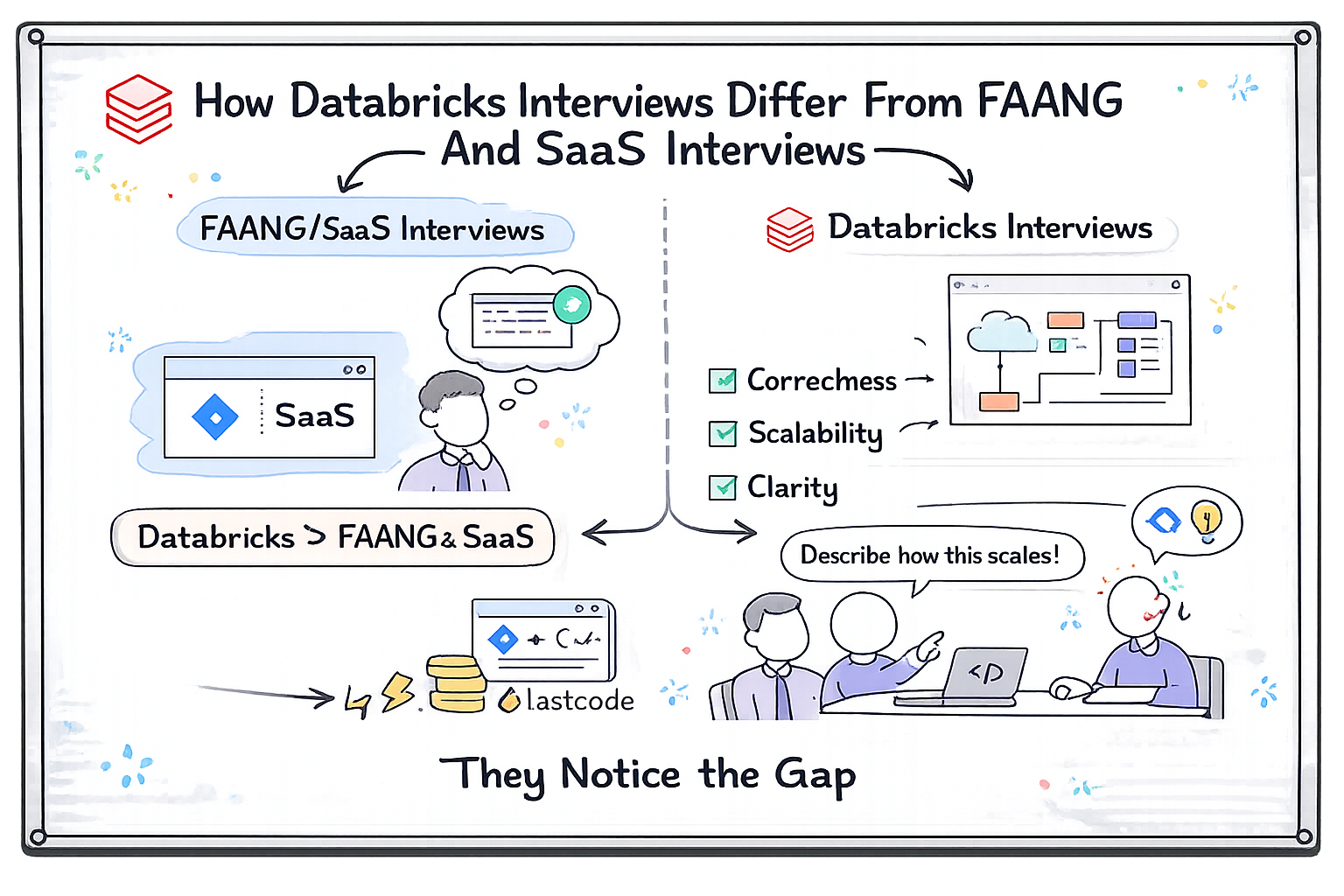
While FAANG interviews often emphasize algorithmic mastery, Databricks interviews emphasize system behavior. Correctness, scalability, and operational clarity matter more than solving problems as fast as possible.
Candidates who focus only on LeetCode-style preparation often struggle to articulate how their solutions behave at scale. Databricks interviewers notice that gap immediately.
Databricks Interview Process Explained End-to-End
Understanding the structure of the Databricks interview process allows you to prepare intentionally instead of reactively. While details vary by role, the overall flow is consistent.
Recruiter Screen And Role Alignment
The recruiter screen focuses on your background, experience with data systems, and role alignment. You may be asked about distributed systems exposure, data engineering work, or large-scale platform development.
This conversation sets expectations early. Recruiters want to ensure you understand the nature of Databricks’ work before moving forward.
Initial Technical Screen Or Coding Round
The first technical round typically involves a coding problem that emphasizes correctness and reasoning. You are expected to think aloud, clarify assumptions, and discuss complexity.
Databricks interview questions at this stage often include constraints that force you to consider scale, even if the core problem seems simple.
Virtual Or Onsite Interview Loop Structure
The final interview loop includes multiple rounds focused on coding, system design, data engineering concepts, and behavioral evaluation. These rounds are designed to complement each other rather than repeat the same signal.
Interviewers compare notes to assess consistency across problem-solving styles.
Typical Databricks Interview Loop Breakdown
| Interview Stage | Primary Focus | Evaluation Emphasis |
| Recruiter Screen | Role Fit | Background alignment |
| Coding Screen | Problem Solving | Correctness at scale |
| System Design | Distributed Systems | Trade-offs and clarity |
| Data Concepts | Platform Knowledge | Practical understanding |
| Behavioral Round | Collaboration | Ownership and communication |
What Databricks Is Really Testing In Coding Interview Questions
Databricks coding interview questions are designed to test how you think about data and scale, not just whether you can write syntactically correct code.
Correctness At Scale Is The Primary Signal
A solution that works for small inputs but fails under large datasets is considered incomplete. Databricks interviewers expect you to think about input size, memory constraints, and performance from the start.
You should naturally discuss time complexity, space usage, and how your approach behaves when data no longer fits in memory.
Why Assumptions Matter More Than Speed
Databricks interview questions often hide complexity behind simple problem statements. Interviewers want to see whether you ask the right questions before coding.
Rushing into implementation without clarifying constraints can lead to solutions that break under realistic workloads.
How Interviewers Evaluate Communication And Reasoning
Clear communication is essential. You are expected to explain your approach, justify trade-offs, and adapt based on feedback.
Interviewers listen for structured thinking rather than raw speed. Silence without progress or rambling without clarity both work against you.
Common Databricks Coding Interview Question Patterns And Variations
Databricks interview questions are grounded in fundamental algorithmic patterns, but they are shaped by data-intensive use cases.
Algorithmic Patterns Databricks Frequently Uses
Common patterns include array and string manipulation, hashing and grouping, graph traversal, and dynamic programming. These patterns often appear in the context of data transformation, aggregation, or dependency resolution.
The emphasis is on choosing the right abstraction and understanding how it scales.
How Databricks Introduces Distributed Complexity
Databricks often adds constraints related to distribution. You may be asked how a solution would change if data is partitioned across machines or streamed instead of processed in a batch.
This is where candidates with real-world data experience tend to stand out.
Common Patterns And What Databricks Evaluates
| Pattern Type | Typical Use Case | What Interviewers Look For |
| Arrays And Strings | Data preprocessing | Boundary handling |
| Hashing And Grouping | Aggregations | Memory awareness |
| Graph Traversals | Dependency tracking | Scalability |
| Dynamic Programming | Optimization problems | State clarity |
The Right Mental Model For Databricks Coding Rounds
You should approach Databricks coding interviews like designing a reliable data job. Validate assumptions early. Consider failure modes. Think about how your solution behaves as data grows.
Databricks interviewers are less interested in how fast you type and more interested in how well you understand the system you are building.
Databricks System Design Interview Questions For Distributed Systems
Databricks system design interview questions are where the company’s core identity becomes most visible. These interviews are not about designing consumer-facing features. They are about building platforms that process massive volumes of data reliably across distributed environments.
What Databricks Expects From A System Design Discussion
You are expected to start by clarifying the problem space and defining non-negotiable requirements. Databricks interviewers look for engineers who can impose structure on complex, data-heavy problems.
The conversation quickly moves toward scale. You should expect to discuss data size, throughput, latency, fault tolerance, and recovery strategies early in the design.
Designing Data Pipelines At Scale
Many Databricks system design interview questions revolve around data pipelines. You may be asked to design batch processing systems, streaming pipelines, or hybrid architectures.
Interviewers want to see whether you understand how data flows through systems, how it is partitioned, and how failures are handled without corrupting results.
Batch Versus Streaming Design Trade-Offs
You should be comfortable discussing when batch processing is appropriate and when streaming is necessary. Databricks interviewers often probe how you reason about latency requirements, state management, and complexity.
Strong candidates explain trade-offs clearly and choose designs based on use-case constraints rather than personal preference.
System Design Evaluation Focus
| Design Area | Why It Matters At Databricks | What Interviewers Evaluate |
| Scalability | Massive datasets | Horizontal growth |
| Fault Tolerance | Long-running jobs | Recovery strategies |
| Data Correctness | Business trust | Idempotency |
| Observability | Debugging failures | Monitoring clarity |
How Databricks Evaluates Trade-Offs In Data-Intensive Systems
Trade-offs sit at the center of Databricks interview questions. There is rarely a single correct answer. What matters is whether you understand the consequences of your decisions.
Latency Versus Throughput In Data Platforms
Databricks systems often optimize for throughput rather than low latency, but this is not universal. Interviewers want to see whether you understand how design choices affect both.
You should be able to explain how batching improves throughput and how streaming reduces latency, along with the operational costs of each.
Consistency Versus Availability Decisions
Distributed systems force trade-offs between consistency and availability. Databricks interviewers expect you to reason about these decisions in practical terms rather than theoretical abstractions.
You should be able to explain how consistency guarantees affect downstream users and why eventual consistency may or may not be acceptable.
Cost Versus Performance Trade-Offs
Databricks operates in cloud environments where cost is a real constraint. Interviewers often probe how you think about resource usage, scaling strategies, and performance optimization.
Strong answers acknowledge cost implications and justify resource-heavy decisions when they are necessary.
Databricks Behavioral Interview Questions
Databricks behavioral interview questions are designed to assess how you operate in a highly collaborative, cross-functional environment. Building a data platform requires coordination across engineering, product, and data teams.
Why Collaboration Matters At Databricks
Databricks engineers often work across boundaries, supporting internal teams and external customers. Behavioral interviews evaluate whether you can communicate complex technical concepts clearly and work effectively with non-specialists.
Interviewers look for examples that demonstrate empathy, patience, and ownership.
Ownership In Long-Running Systems
Many Databricks systems run continuously and evolve over time. Behavioral questions often explore how you take responsibility for systems you did not originally build.
Strong answers focus on proactive improvement, documentation, and mentoring rather than short-term fixes.
Handling Ambiguity And Evolving Requirements
Databricks operates in a fast-growing space where requirements change frequently. Interviewers want to know how you respond when priorities shift or when incomplete information is available.
You are expected to demonstrate adaptability without sacrificing data correctness.
Behavioral Evaluation Themes
| Theme | Why It Matters | What Strong Answers Show |
| Collaboration | Cross-team work | Clear communication |
| Ownership | Platform stability | Long-term thinking |
| Ambiguity | Rapid evolution | Structured decisions |
| Learning | Complex systems | Curiosity and growth |
Databricks Backend Interview Questions
Databricks backend interview questions probe how deeply you understand systems that operate at scale. These interviews emphasize correctness, performance, and operational awareness.
APIs And Interfaces For Data Platforms
You may be asked to design APIs that expose data processing functionality. Interviewers look for clarity, stability, and ease of use.
Strong answers consider versioning, backward compatibility, and error handling.
Concurrency And Parallelism In Data Processing
Databricks systems rely heavily on parallelism. Interviewers want to see whether you understand how tasks are scheduled, how resources are shared, and how concurrency affects correctness.
Conceptual understanding must translate into practical reasoning.
Debugging And Observability In Distributed Systems
Databricks interview questions often include debugging scenarios. You may be asked how you would diagnose slow jobs, data inconsistencies, or partial failures.
Interviewers value systematic approaches that rely on metrics, logs, and tracing rather than guesswork.
Backend Evaluation Focus Areas
| Backend Area | Why It Matters At Databricks | What Interviewers Evaluate |
| APIs | Platform usability | Contract clarity |
| Parallelism | Performance | Safe execution |
| Resource Management | Cost control | Efficient usage |
| Observability | Reliability | Diagnostic skill |
Mistakes Candidates Make When Preparing For Databricks Interviews
Many candidates underestimate Databricks interview questions because they assume the interviews will resemble standard Big Tech coding rounds. In reality, most failures happen because candidates prepare too narrowly and miss the systems-oriented nature of the role.
Treating Databricks Like A Pure Algorithm Interview
One of the most common mistakes is focusing exclusively on algorithm puzzles without considering how solutions behave at scale. Databricks interviewers expect you to think beyond correctness for small inputs and reason about performance, memory usage, and data growth.
A solution that ignores scale feels incomplete, even if the logic is correct.
Over-Focusing On Spark APIs Instead Of Concepts
Some candidates assume deep Spark API knowledge is required and spend excessive time memorizing functions. Databricks interviews rarely reward API recall. What matters is whether you understand distributed data processing concepts such as partitioning, shuffling, and fault tolerance.
Interviewers care far more about why a system behaves a certain way than which function you use to implement it.
Ignoring Behavioral Preparation
Databricks places significant emphasis on collaboration and ownership. Candidates who skip behavioral preparation often struggle to explain how they work across teams or handle production issues.
Weak behavioral answers can undermine otherwise strong technical performance.
Not Asking Clarifying Questions
Databricks interview questions often begin with intentionally vague requirements. Failing to clarify assumptions early leads to designs that break under realistic constraints.
Interviewers expect you to define the scope before committing to solutions.
How To Prepare For Databricks Interview Questions: A 6 To 8 Week Plan
Preparing effectively for Databricks interview questions requires a balanced approach that blends algorithms, distributed systems, and communication skills.
Weeks One And Two: Strengthening Foundations
In the early phase, your focus should be on core data structures and algorithmic thinking, with an emphasis on clarity and correctness. At the same time, you should refresh foundational distributed systems concepts such as consistency, fault tolerance, and parallelism.
This is also a good time to practice explaining your thinking out loud.
Weeks Three And Four: Building Distributed Systems Intuition
During this phase, shift your focus toward system design and data-intensive problems. Practice reasoning about batch versus streaming systems, scalability limits, and failure recovery.
Mock interviews become especially valuable here because they expose gaps in communication and structure.
Weeks Five And Six: Refinement And Confidence Building
The final phase should focus on consistency and confidence. You should aim to perform well across coding, design, and behavioral rounds without mental fatigue.
Behavioral preparation should emphasize ownership, collaboration, and learning rather than polished storytelling.
Preparation Focus By Phase
| Preparation Phase | Primary Objective | Skill Emphasis |
| Weeks 1–2 | Foundations | Correct reasoning |
| Weeks 3–4 | Systems Thinking | Trade-offs |
| Weeks 5–6 | Consistency | Clear communication |
| Weeks 7–8 | Optional Buffer | Mock interviews |
Final Checklist Before Your Databricks Interview
Before entering your Databricks interview, you should evaluate your readiness honestly. Databricks interview questions surface gaps quickly.
You should feel comfortable reasoning about data that does not fit in memory, explaining how systems behave under failure, and defending trade-offs clearly. You should be able to adapt your approach when constraints change and explain why adjustments are necessary.
Confidence comes from preparation that mirrors real work, not from memorization.
Calm Under Ambiguity
Databricks interviewers value engineers who remain calm when requirements are incomplete. Demonstrating structure and clarity under ambiguity signals readiness for platform-level work.
What Success In Databricks Interviews Actually Looks Like
Success at Databricks is not about having the most impressive background or the fastest solution. It is about demonstrating that you can think like a platform engineer.
Interviewers look for candidates who understand how data systems evolve, how failures are mitigated, and how trade-offs affect users downstream. You do not need to know everything, but you must reason clearly about what you know and what you do not.
Consistency across interviews matters more than perfection in a single round.
Structured learning and interview prep resources
A patterns-based resource like Grokking the Coding Interview Patterns reinforces the thinking Databricks wants: clear logic, reusable problem-solving frameworks, and careful reasoning.
Final Thoughts
Databricks interview questions are designed to reflect the reality of building and maintaining large-scale data platforms. These interviews reward engineers who think in systems, communicate clearly, and respect the complexity of data at scale.
When you prepare with that perspective, your approach changes. You stop chasing clever solutions and start focusing on correctness, scalability, and reliability. You treat interviews as collaborative problem-solving sessions rather than tests to survive.
That shift is what allows strong candidates to perform with confidence and clarity.
If you prepare intentionally and practice thinking out loud, Databricks interviews become an opportunity to demonstrate how you would actually work as an engineer on the platform, not just how well you can solve isolated problems.